
In the past few years, two major patterns in our consumption of online content have come to light — the proliferation of misinformation (or “fake news” as Trump would say) and the entrapment of users in personal filter bubbles. This was especially true during the 2016 US Election and is becoming increasingly prominent in my home country of India, where I constantly see family members being swayed by an article or a claim that panders to their inherent bias. The alarming part is that false (or somewhat false) “news” is no longer limited to dodgy blog sites and virus-ridden webpages but also posts on social media by influential people (read: politicians) with valid credentials and a large following.
As a generation that grew up bombarded by information owing to the boom of the Internet and social media, many of us have learned to filter out certain things (or at the very least, question it) when we realize the source may have something to gain. However, our parents and their parents have always received information from somewhat credible sources and have never had to fact-check leaders of nations or the news, which is believed to be the absolute, objective truth. And even if one has learned to Google something before trusting it, it is not always easy to judge misinformation as it is usually wrapped around some truth, which can allow it to get past our checks (especially if it agrees with our bias and provides a target for our frustrations).
Additionally, what doesn’t help the cause is the fact that social media algorithms are solely built around engagement & likes, which means we’re constantly being fed information that agrees with past content we’ve interacted with regardless of whether any of it is grounded in reality. This lack of perspective and resulting lack of empathy is dangerous and can be easily taken advantage of.
Thus, I pitched an idea to tackle this very problem to my team (Chaitanya, Nikhil & Bobby) and in the recent NUS Hack&Roll 2018, we decided to build it.
Finding a Solution
Misinformation is an especially hard problem to solve because the people you’re trying to solve it for might not actually want a solution. Let me try to explain. Let’s say you’re an X (any form of identity — nationality, religion, section of society) and you read something about how X-people are great and Y-people are responsible for your Z (any problem — unemployment, lack of government support). You will automatically be inclined to believe this statement because 1) it praises X, 2) it refers to a real problem Z you’re facing and 3) it gives you a target Y to blame for Z. Now, if I tell you the statement is false and that Z is caused by X & Y or maybe even solely by X, your initial instinct will be to get defensive and discard what I said as untrue because I have suddenly robbed you of your external target and pushed some of the blame onto X (and by way of identity, you).
Furthermore, any algorithm that simply tries to check whether a statement is true/untrue (assuming the world is not ambiguous) will eventually develop its own bias and you’re back to square one. This is why automated “truth meters” or fake news classifiers are not going to be able to completely solve these issues. What we need is a way to allow people to rationalize an informed decision on their own by providing more than one (reliable) side to a story, primarily a side that disagrees with their beliefs assuming it exists.
That’s where Context News Bot comes in.
Context News Bot

Context News Bot is a Chrome extension that attaches itself to your Twitter timeline and provides a one-click solution to retrieving diverse perspectives on an issue. It does this by running the tweet you’ve selected through a natural language pipeline (built on top of Google Cloud Natural Language API) and extracting the important entities in the tweet & sentiments associated with them. Next, it uses this information to form search keywords to retrieve relevant news articles from a variety of reliable sources after which the retrieved articles are scored on their relevance based on our own heuristic (explained below) and the top articles are delivered to the user for easy reading. Along with the top articles, we also try to retrieve a relevant Wikipedia entry to provide an objective collection of facts regarding the issue.
By providing more context to the tweet, we aim to enable users to make a more informed decision on the knowledge they absorb through Twitter.
The entire source code can be found on GitHub and further technical details can be found on the DevPost page. You can also try the system yourself by following the instructions on the GitHub README.
Retrieving News Articles
We retrieve the initial news articles from the News API by creating search phrases from the important entities mentioned in the tweet, the geotag of the tweet and the name of the user tweeting (if he/she is verified). We differentiate important entities from non-important ones by checking if their type belongs to one of ["PERSON", "LOCATION", "ORGANIZATION", "EVENT", "WORK_OF_ART", "CONSUMER_GOOD"]. Lastly, because tweets can be about incidents that happened weeks/months/years ago, we retrieve all the relevant news articles as opposed to the top headlines at that moment in time.
Selecting News Articles
Because we had to hack out a prototype in 24 hours and didn’t have access to a dataset that mapped tweets to news articles (to train a custom model or otherwise), we used a custom heuristic to score an article on its relevancy to a tweet. The heuristic uses the entity information outputted by Google’s API in a weighted approach by taking into account every matching entity’s type, saliency & number of mentions:
total_score = 0
# matching_entities are the entities found in the tweet and news article.
for entity in matching_entities:
# REALLY_IMP_ENTITY_IDX are the indexes for "PERSON", "LOCATION", "ORGANIZATION"
# & "EVENT" entity types.
if entity.type in REALLY_IMP_ENTITY_IDX:
total_score += (entity.salience * 1.5) * min(3, len(entity.mentions))
else:
total_score += entity.salience * min(3, len(entity.mentions))
Once we score all the articles, we filter them out by source (no more than one article from a single source) and sentiment to deliver a diverse set of views to the user.
Client User Interface
In order to make the user interface as non-intrusive and intuitive as possible, we simply integrated an action button into every tweet with the other existing buttons as below:
Once the button is clicked, it loads up the news articles as cards (which seamlessly blend with Twitter’s native UI) below the tweet along with each tweet’s sentiment color (green for positive, orange for neutral and red for negative):
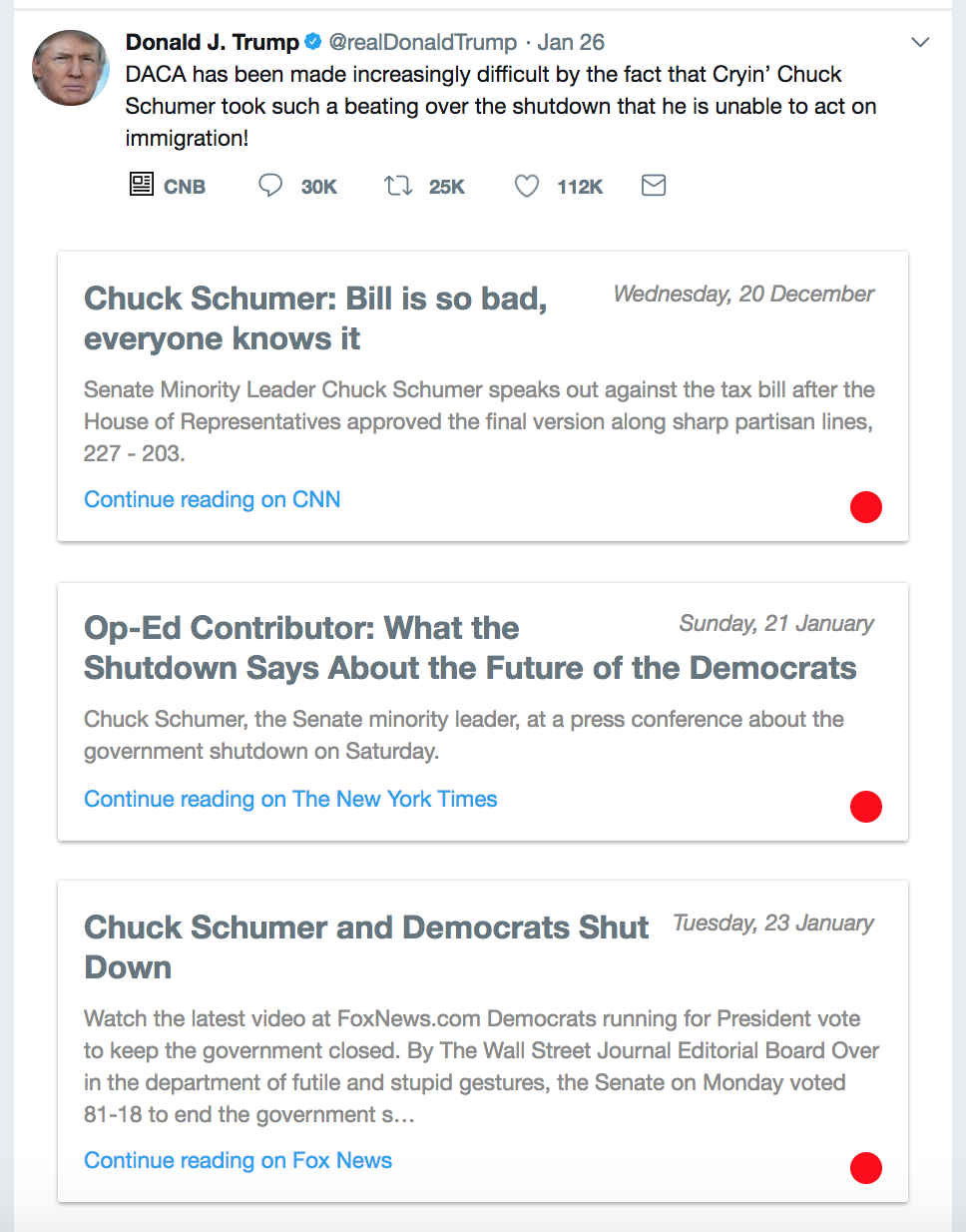
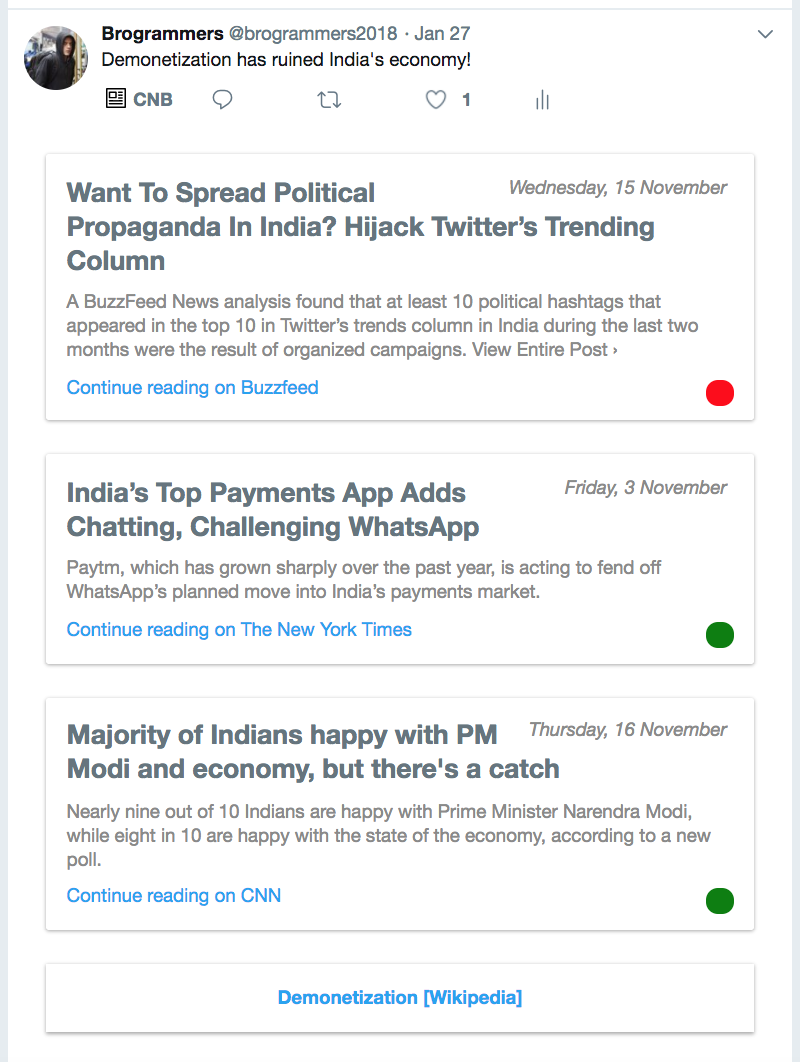
In the case that an appropriate Wikipedia entry is found, it is provided below the news articles:
What’s next?
We want to work on increasing the accuracy of our (currently rudimentary) pipeline in order to retrieve relevant news articles every single time, integrate with other social networks and lose the dependencies on external APIs, particularly for the natural language processing tasks whose calls are especially expensive. You can help us out by contributing to our GitHub repo!
Side Note: We won!
As an added bonus to building a complete prototype of something we consider to be of utmost importance within 24 hours, we also ended up winning a Top 8 prize and Most Socially Useful Hack at the hackathon!

Photo of the team (minus Chaitanya) with our winning loot!